






2003年4月19日
第一章 緒論
2003年3月12日台大語音實驗室受委託對三集中國中央電視台的焦點訪談節目做檢驗,檢驗的內容為驗證兩位在三集中連續出現的人物-劉葆榮及王進東-是否真如節目所宣稱的為同一人。
此三集錄影是中國中央電視台播出的焦點訪談節目,內容為2001年1月23日天安門廣場自焚事件的調查及訪談。其中劉葆榮和王進東為自焚未遂者。劉葆榮在第一集和第二集出現接受採訪,王進東則在全部三集均有出現接受採訪。第一集訪問劉葆榮時的錄音環境為安靜的室內,第二集則是劉葆榮家的臥房。
第一集訪問王進東的環境為醫院的病房,第二集前半為有迴音的走廊,後半為安靜的大房間,第三集亦為安靜的大房間。不同的錄音條件對語者驗證結果的可信度構成了極大的考驗。本章後半部分將討論本報告所採用的解決方法。
台大語音實驗室多年來致力於提升中文語音辨識技術,已累積豐碩的成果。本測試實驗係以2001年6月研究生鍾偉仁在其畢業學位論文中所研發的語者驗證(Speaker Verification)技術為基礎進行【1】。
語者驗證(Speaker Verification)是一種根據說話者的語音與其所宣稱的身份,驗證說話者是否真如其人的技術。相關的研究在國際上可追溯到許多年前。常見的用途包括金融交易,犯罪偵防等。
根據【1】,常用於語者驗證的模型有高斯混合模型(Gaussian Mixture Model, GMM)、隱藏式馬可夫模型(Hidden Markov Model, HMM)、及特性語音(Eigenvoice)。其中高斯混合模型是隱藏式馬可夫模型的簡化,原理為把同一語者的訓練語料(Training Corpus)依聲學特性分群,然後把每一群聲學特性用一個高斯分佈來描述。高斯混合模型也是本報告所使用的方法。
隱藏式馬可夫模型在語者驗證的表現比高斯混合模型好【1】,但因系統較為複雜且需要更多的訓練語料,因此並不適合用於本測試。特性語音因其表現不如高斯混合模型【1】,因此亦不採用。
如本章開頭所述,不同的錄音條件對語者驗證構成了極大的困難。因為不同的錄音條件可以造成就算是兩段同一個人的講話錄音,也可能因環境的差異(如不同的麥克風、不同的噪音、及不同的迴音等)而被驗證為不同一人。此種情形稱為False Rejection。 False Rejection是說話者的確為其所宣稱的身份,但卻被系統拒絕(Reject)的情況。相反地,False Acceptance則是說話者並非其所宣稱的身份,但卻被系統接受(Accept)的情況。通常False Rejection及False Acceptance二者無法兼顧,亦即其間是互相取捨(Trade-off)的關係,亦即將其中一個降低的時候(如提高或降低門檻值時),另一個一定會上升。
為了達到可信度的要求,本測試實驗設計為讓False Rejection的可能性儘量地低,而False Acceptance的可能性儘量高。這樣一來,因為False Rejection的可能性很低,所以如果系統仍然判定為Rejection,則其為正確(的Rejection)的可能性就大大地提高。
因為本測試實驗採用門檻值(Threshold)做為判定接受(Accept)或拒絕(Reject)的標準,高於門檻值即接受,低於門檻值即拒絕,因此選擇一個合理但較低的門檻值即可達到降低False Rejection但提高False Acceptance的目的。
觀察三集節目,可發現採訪受訪者的女記者多次出現在節目中,且其錄音的條件包含最多種不同的情況(如外場、醫院、臥室,監獄,走廊等)。因此如果可以適當地設計門檻值使這些不同錄音條件的語音片段都被驗證為同一個人,即門檻值低到讓這些女記者的語音片段都被系統接受,則可以達到最大的可信度。(注:三集中進行採訪的女記者並不一定都是同一人,但因為是考慮最差情況也要驗證通過,因此並不影響)
第二章 理論背景
2.1 語者驗證器本報告所使用的語者驗證器為一種對數相似值比偵測器(Log-Likelihood Ratio Detector),如下圖:
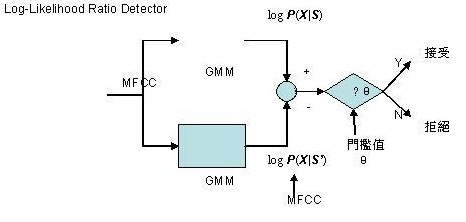
當測試語音經過前端處理抽取出特徵向量(Feature Vector)後,分別將特徵向量對語者特定模型及語者背景模型作對數相似度(Log-Likelihood)的計算,然後再相減得到最後的分數。這麼做的目的是使最後的分數降低對語者自己語音的變異性(Inner-Speaker Variation),但留下語者間的變異性(Inter-Speaker Variation)【1】。
2.2 語者背景模型(Background Speaker Model)
語者背景模型用來在語者驗證中幫助分數的正規化動作,使分數降低對語者自己語音的變異性(Inner-Speaker Variation),但留下語者間的變異性(Inter-Speaker Variation)【1】。
在規模比較大的語者驗證系統中,為了簡化系統設計的複雜度,通常就拿語者不特定模型(Speaker Independent Model)來當成每一位語者的背景模型【1】。
語者不特定模型由全部語者的語料訓練得到。
2.3 語者特定模型(Speaker Dependent Model)
語者特定模型的目標是模擬每一位語者的聲學特徵。每一位語者的模型都代表該位語者的語音聲學特性。語者特定模型由語者不特定模型經由貝氏調適法調適而來,調適的語料即為該位語者的語料。
第三章 實驗方法及結果
3.1 錄音將三集節目(zf1.rm、zf2.rm、zf3.rm)經由RealPlayer播放的同時啟動音效卡直接將聲音訊號錄製下來(在音效卡內部播放同時錄製,並不經由任何外部的導線)。取樣參數為:
| 取樣頻率(Sampling Rate) | 8kHz |
| 取樣大小(Sample Size) | 16bit |
| 聲道(Channels) |
2 |
3.2切音在前述錄製下來的聲音中切出需要的片段如下:
名稱 |
語者 |
來源 |
長度(分:秒) |
時間分佈 |
| Zf1_liubaorong | 劉葆榮 | Zf1.rm | 2:36 | 1:34-1:43* 2:06-2:17* 2:22-2:34* 2:39-2:59* 3:09-3:47* 4:55-5:30 9:54-10:11 15:17-15:40* |
| Zf2_liubaorong | 劉葆榮 | Zf2.rm | 0:32 | 6:40-7:30* |
| Zf1_wangjindong | 王進東 | Zf1.rm | 0:06 | 4:30-4:34 13:10-13:21* 13:30-13:31* |
| Zf2_wangjindong | 王進東 | Zf2.rm | 0:30 | 9:06-9:24* 9:58-10:20* |
| Zf2_wangjindong2 | 王進東 | Zf2.rm | 4:08 | 10:28-10:40* |
| Zf3_wangjindong | 王進東 | Zf3.rm | 0:55 | 9:07-9:22 9:30-10:13 |
| Zf1_reporter | 訪問劉思影的女記者 | Zf1.rm | 0:05 | 9:11-9:18* |
| Zf1_reporter2 | 訪問劉雲芳的女記者 | Zf1.rm | 0:09 | 12:36-12:44* |
| Zf1_reporter3 | 訪問王進東的女記者 | Zf1.rm | 0:07 | 13:07-13:18* |
| Zf1_reporter4 | 訪問何海華、王娟的女記者 | Zf1.rm | 0:15 | 13:44-13:48* 13:52-14:01* |
| Zf1_reporter5 | 訪問劉葆榮的女記者 | Zf1.rm | 0:05 | 15:22-15:28* |
| Zf2_reporter | 訪問陳果的女記者 | Zf2.rm | 0:15 | 3:05-3:06 4:02-4:53* |
| Zf2_reporter2 | 訪問郝惠君的女記者 | Zf2.rm | 0:11 | 3:48-3:50 5:45-6:03* |
| Zf2_reporter3 | 訪問崔麗的女記者 | Zf2.rm | 0:05 | 5:35-5:42* |
| Zf2_reporter4 | 訪問劉葆榮的女記者 | Zf2.rm | 0:03 | 6:51-6:53 |
| Zf2_reporter5 | 訪問劉雲芳的女記者 | Zf2.rm | 0:03 | 8:09-8:11 |
| Zf2_reporter6 | 訪問王進東的女記者 | Zf2.rm | 0:03 | 9:01-9:05* |
| Zf2_reporter7 | 第二次訪問王進東的女記者 | Zf2.rm | 0:31 | 10:59-12:00* 16:21-16:27 |
| Zf3_reporter | 訪問馮海軍的女記者 | Zf3.rm | 0:13 | 2:04-2:13* 3:05-3:25* |
| Zf3_reporter2 | 訪問馬樂的女記者 | Zf3.rm | 0:16 | 4:22-4:25 |
* 中間旁白或其他人的聲音,已去除其中Zf1_liubaorong的長度為2分36秒,Zf2_wangjindong2的長度為4分08秒,因其長度最長,分別做為訓練劉葆榮及王進東的語者特定模型的語料。因為女記者的語料長度都太短,無法訓練模型,因此再將女記者的語料依節目組合如下:
| Zf1_reporter_all | Zf1_reporter + zf1_reporter2 + zf1_reporter3 + zf1_reporter4 + zf1_reporter5 |
| Zf2_reporter_all |
Zf2_reporter + zf2_reporter2 + zf2_reporter3 + zf2_reporter4 + zf2_reporter5 + zf2_reporter6 + zf2_reporter7 |
| Zf3_reporter_all | Zf3_reporter + zf3_reporter2 |
| Reporter-1_2 |
Zf1_reporter_all + Zf2_reporter_all |
| Reporter-2_3 | Zf2_reporter_all + Zf3_reporter_all |
| Reporter-1_3 |
Zf1_reporter_all + Zf3_reporter_all |
其中Reporter-1_2、Reporter-2_3、及Reporter-1_3分別用來訓練三個不同的語者特定模型,分別與Zf3_reporter_all、Zf1_reporter_all、及Zf2_reporter_all做驗證,以訓練門檻值。最後還有一個訓練語者不特定模型的語料:
| ZFAll_vocal |
三集節目中所有的語音 |
3.3 抽取特徵向量(Feature Vector)本報告所使用的語音特徵向量(Feature Vector)為39維的MFCC(Mel-Frequency Cepstral Coefficient)係數:
| 預強調濾波器(Pre-emphasis Filter) |
1-0.97z-1 |
| 音框長度(Frame Size) |
32ms |
| 音框平移(Frame Shift) |
10ms |
| 濾波器組(Filter Bank) | 梅爾刻度三角濾波器組(Mel-Scale Triangular Filter Banks) |
| 濾波器數(Number of Filter Bank) | 26 |
| 低頻截止頻率 (Low Cut-off frequency) |
300Hz |
| 高頻截止頻率 (High Cut-off Frequency) |
3400Hz |
| 特徵向量(Feature Vector) | 12維爾頻率倒頻譜係數加時間軸上正規化之短時能量(MFCC_E)加一階及二階回歸係數(MFCC_E_D_A)共39維 |
抽取特徵向量的程式是藉由HTK 3.0所附的HCopy【2】。
3.4 訓練語者不特定模型(Speaker Independent Model)訓練語料為ZFAll_vocal。訓練的方式是先由向量量化(Vector Quantization)求得初始模型,當群數小於8時,使用K平均值修正法(Modified K-means);當群數大於8後,改用二值分裂法(Binary Split)。得到初始模型後再做期望值最大化(Expectation Maximization)得到最終的模型【1】。根據【1】,在高斯混合模型的語者驗證實驗中,混合數(Number of Mixtures)為512或1024時驗證錯誤率為最低。為簡少計算量,因此本報告取混合數為:
| 混合數(Number of Mixtures) |
512 |
3.5調適語者特定模型(Speaker Dependent Model)語者特定模型由上一節所述的語者不特定模型(ZFAll_vocal)經由貝氏調適法調適而來。且只對平均值向量作調適,而混合加權值及變異量則用語者不特定模型的參數代替【1】。本報告所用到的語者特定模型及其調適語料如下:
語者特定模型 |
調適語料 |
| Zf1_liubaorong.sd.model |
Zf1_liubaorong |
| Zf2_wangjindong2.sd.model | Zf2_wangjindong2 |
| Reporter-1_2.sd.model | Reporter-1_2 |
| Reporter-2_3.sd.model | Reporter-2_3 |
| Reporter-1_3.sd.model | Reporter-1_3 |
3.6語者驗證由2.1圖,最後計算每段測試語音的驗證分數的公式為:
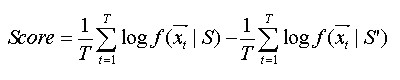
T為測試語音的音框數, 為時間t時的特徵向量,S及S’分別為語者特定模型及語者不特定模型。驗證分數:
模型(SD Modal) |
測試語料 |
分數(Score) |
| Zf1_liubaorong | Zf2_liubaorong | -0.042003 |
| Zf2_wangjindong2 |
Zf1_wangjindong | -0.201615 |
| Zf2_wangjindong | 0.128923 | |
| Zf3_wangjindong | 0.325247 | |
| reporter-1_2 |
Zf3_reporter_all | 0.146295 |
| reporter-2_3 |
Zf1_reporter_all | 0.022340 |
| reporter-1_3 |
Zf2_reporter_all | 0.012399 |
上表第一列為以第一集的劉葆榮訪問內容訓練模型,驗證第二集的劉葆榮的聲音的分數。第二、三、四列分別為以第二集第二次訪問王進東的內容訓練模型,驗證第一集、第二集第一次、及第三集訪問王進東的內容。第五列為以第一集、第二集的女記者聲音為訓練語料,驗證第三集的女記者聲音的分數。第六、七列類推。如第一章所述,為了取得可信度,因此設計門檻值為使這三段女記者的測試語料都通過驗證,所以取第五、六、七列分數的最小值為門檻值,即0.012399。
| 門檻值(Threshold) |
0.012399 |
驗證結果為:
參考語者 |
測試語者 |
分數(Score) |
門檻值 |
驗證結果 |
第一集的劉葆榮(Zf1_liubaorong) |
第二集的劉葆榮(Zf2_liubaorong) |
-0.042003 |
0.012399 |
拒絕 |
第二集的第二次訪問 王 進 東 (Zf2_wangjindong2) |
第一集的王進東 (Zf1_wangjindong) |
-0.201615 |
拒絕 |
|
第二集的第一次訪問 王 進 東 (Zf2_wangjindong) |
0.128923 |
接受 |
||
第三集的王進東(Zf3_wangjindong) |
0.325247
|
接受 |
||
第一、二集的女記者 (reporter-1_2) |
第三集的女記者 (Zf3_reporter_all) |
0.146295 |
接受 |
|
第二、三集的女記者 (reporter-2_3) |
第一集的女記者 (Zf1_reporter_all) |
0.022340 |
接受 |
|
第一、三集的女記者 (reporter-1_3) |
第二集的女記者 (Zf2_reporter_all) |
0.012399 |
接受 |
驗證結果為接受意指該測試語者與參考語者(即訓練模型的語者)經本測試判定為同一人,拒絕意指判定為不同一人。因此由上表,在本實驗所設定的「儘可能把False Rejection降至最低」,亦即「儘可能不去拒絕」,或「只要兩段聲音有一定相似度,就會被接受」的條件下,在本實驗所擁有的語料下所測試的結果為第一集的劉葆榮與第二集的劉葆榮應可判斷不是同一人,第二集的第一、二個王進東與第三集的王進東應可判斷是同一人,第一集的王進東與其餘兩集的王進東應可判斷不是同一個人。
第四章 結論
本篇報告經由高斯混合模型的語者驗證技術,判別出了焦點訪談錄像中第一集的劉葆榮與王進東分別與第二集的劉葆榮與王進東應可判斷不是同一個人的結論。在3.3節中,本篇報告採用混合數為512的模型,其實本篇報告亦有做混合數為256或128的實驗,除了數字少許不同外,結論(驗證接受或拒絕)卻是完全相同的。
參考文獻
【1】 鍾偉仁,”語者辨認與驗證之初步研究(An Initial Study on Speaker Recognition and Verification)”,2001年,國立台灣大學電信工程學研究所 碩士學位論文
【2】 Steve Young, Dan Kershaw, Julian Odell, et. al, "The HTK Book (for HTK version 3.0)”, July 2000
最后更新 ( 2004-07-26 15:10 )
| • 下一篇:科学鉴定揭示"天安门自焚”真相 2003.-5.13 |
| • 上一篇:追查迫害法轮功国际组织关于调查所谓“天安门自焚事件”的通告(更新)(图) 2003.1.23 |